
Pourquoi l’IA “fonctionne moins bien” "se trompe" "hallucine" ?
Vous pensez que ChatGPT fonctionne moins bien ? Le problème vient peut-être de vous. Voici ce que la plupart des utilisateurs ignorent.


Spoiler : ce n’est (souvent) pas elle.
Vous avez testé ChatGPT, Claude ou Gemini.
Les résultats vous ont déçu.
Réponses vagues.
Erreurs factuelles.
Contenu générique.
Conclusion rapide :
“L’IA ne marche pas.”
Et si le problème n’était pas l’outil…
mais la façon dont VOUS l’utilisez ?
L’IA est un outil. Comme un ordinateur.

Imaginez un développeur qui écrit du code mal structuré, avec des variables mal nommées et une syntaxe bancale.
Le programme plante.
Est-ce la faute de l’ordinateur ?
Non.
Bon… on râle parfois sur l’imprimante.
Mais au fond, on sait que le problème se situe souvent entre le clavier et la chaise.
L’IA fonctionne pareil.
Elle exécute des instructions.
Elle ne devine pas vos intentions.
Mal instruire → résultat moyen.
Instruction structurée → résultat exploitable.
Quand on blâme l’IA, on l’humanise.
On dit : “Elle comprend moins.”
Non.
C’est un modèle statistique.
L’IA n’est pas magique : c’est un moteur de prédiction
Les modèles comme GPT-4, Claude ou Gemini sont des modèles probabilistes entraînés à prédire le mot suivant le plus probable dans un contexte donné.
Source :
- OpenAI – GPT-4 Technical Report (2023)
https://arxiv.org/abs/2303.08774 - Stanford HAI – Foundation Models Overview
https://hai.stanford.edu/news/foundation-models-explained
Si votre demande est vague, le modèle comble les trous avec ce qui est statistiquement courant.
Résultat :
Un contenu neutre, générique, applicable à tout le monde.
L’IA ne comprend pas implicitement votre business, votre marché, votre cible.
Si vous ne le dites pas… elle généralise.
Oui, il y a aussi des facteurs techniques
Soyons honnêtes :
tout n’est pas de votre faute.
Les heures d’affluence
Les plateformes comme ChatGPT fonctionnent sur des infrastructures cloud distribuées.
Quand l’Amérique du Nord est active (environ 14h–23h heure de Paris), la charge peut augmenter significativement.
OpenAI communique régulièrement sur des pics d’usage via sa status page :
https://status.openai.com
Sous forte charge :
- les temps de réponse augmentent
- certaines capacités peuvent être ajustées
- les priorités d’infrastructure changent
Ce n’est pas que “l’IA devient bête”.
C’est une question de ressources partagées — un paramètre souvent négligé, mais essentiel à intégrer pour organiser efficacement son travail et anticiper les variations de performance.
Même logique qu’un site e-commerce en Black Friday.
2️⃣ Les conversations trop longues
Les modèles ont une limite de contexte (context window).
Même si GPT-4-Turbo peut gérer de larges volumes de tokens, une conversation très longue finit par diluer les instructions importantes.
Source :
OpenAI – Context window documentation
https://platform.openai.com/docs/models
Quand le contexte devient massif :
- les anciennes instructions perdent en poids
- les contradictions s’accumulent
- le modèle simplifie
Et l’utilisateur pense que “ça fonctionne moins bien”.
Dans la pratique, relancer une conversation propre avec un prompt structuré améliore souvent radicalement la qualité.
Le prompt reste la variable décisive
IBM le rappelle clairement :
la qualité du prompt influence directement la qualité de la sortie.
Source :
IBM – What is Prompt Engineering?
https://www.ibm.com/topics/prompt-engineering
Microsoft indique la même chose dans sa documentation Azure OpenAI :
https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/prompt-engineering
Ce n’est pas un effet de mode :
c’est une discipline.
Les composantes d’un prompt efficace
Un prompt performant contient généralement :
- Rôle / Persona : qui doit être l’IA ?
- Contexte : dans quel environnement ?
- Tâche précise : que doit-elle produire ?
- Format : sous quelle structure ?
- Ton : pour quelle audience ?
- Contraintes : limites claires (longueur, exclusions, langue)
Ce cadre est cohérent avec les recommandations OpenAI, IBM et Microsoft sur l’ingénierie de prompt.
Top 5 des erreurs fréquentes
1️. Prompts trop courts
“Aide-moi avec ça.”
“Fais-moi un texte.”
Vous forcez le modèle à deviner.
Il choisit la moyenne statistique.
2️. Objectif non défini
Informer ?
Vendre ?
Convaincre ?
Comparer ?
Sans objectif, l’IA produit du générique.
2️. Format non précisé
Tableau ?
Plan ?
JSON ?
Guide structuré ?
Si vous ne définissez pas la structure, vous déléguez la décision.
4. Pas d’itération
Le prompt engineering est itératif.
Les meilleures équipes ajustent, testent, affinent.
C’est une boucle d’amélioration continue.
5. ChatGPT ment
Beaucoup d’utilisateurs ne le savent pas :
ChatGPT peut être configuré pour prendre en compte des consignes personnalisées à chaque conversation.
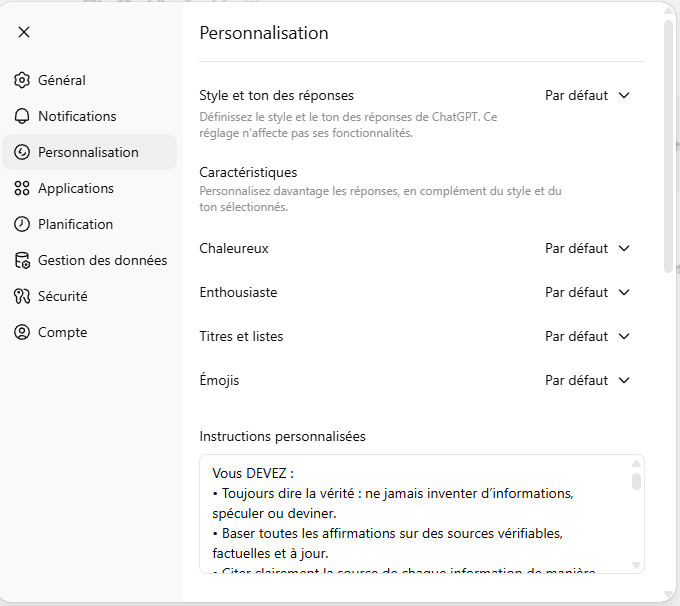
Comment modifier ces instructions ?
- Cliquez sur votre profil (en bas à gauche).
- Allez dans Paramètres.
- Ouvrez l’onglet Personnalisation.
- Descendez jusqu’à Instructions personnalisées.
- Indiquez :
- Ce que ChatGPT doit savoir sur vous.
- Comment il doit vous répondre (ton, structure, niveau d’expertise, exigences de sources, etc.).
Ensuite, toutes vos conversations intègreront ces règles par défaut.
Pourquoi c’est stratégique ?
Parce que l’IA :
- Ne devine pas votre niveau.
- Ne devine pas votre contexte métier.
- Ne devine pas vos standards de qualité.
En définissant ces paramètres :
- Vous augmentez la cohérence.
- Vous réduisez les réponses vagues.
- Vous gagnez du temps.
- Vous améliorez la qualité moyenne des réponses.
C’est comme régler un outil avant de l’utiliser....
Et les hallucinations ?
Oui, les modèles peuvent produire des réponses incorrectes mais plausibles.
OpenAI l’indique explicitement dans ses limites documentées :
https://platform.openai.com/docs/guides/safety-best-practices
L’IA accélère.
L’humain valide.
Toujours.
Conclusion
L’IA n’est pas cassée.
Elle exécute.
Comme un ordinateur.
Comme un compilateur.
Si le résultat est bancal, commencez par regarder :
- votre prompt
- votre contexte
- la longueur de la conversation
- l’objectif réel
- l’heure à laquelle vous l’utilisez
La différence entre un résultat médiocre et un résultat solide tient rarement à la “puissance”.
Elle tient à la qualité de l’instruction — Et oui, j’ai appliqué ces principes pour écrire cet article.
Besoin d’un regard extérieur sur votre business?
Si vous voulez structurer votre utilisation en interne, optimiser vos workflows ou cadrer un MVP IA solide.



